Projects
DeepBurning
Automatic Generation of Deep Learning Accelerators for the famlily of Neural Networks
Recent advances in Neural Networks (NN) are enabling more and more innovative applications. As an energy-efficient hardware solution, machine learning accelerators for deep Convolutional NNs or traditional ANNs are also gaining popularity in the area of embedded vision, robotics and cyberphysics. However, the design parameters of NN models vary significantly from application to application. Hence, it’s hard to provide one general and highly-efficient hardware solution to accommodate all of them, and it is also impractical for the domain-specific developers to customize their own hardware targeting on a specific NN model. To deal with this dilemma, this study proposes a design automation tool, DeepBurning, allowing the application/algorithm developers to build from scratch learning accelerators that targets their specific NN models with custom configurations and optimized performance. DeepBurning includes a RTL-level accelerator generator and a coordinated compiler that generates the control flow and data layout under the user-specified constraints. The results can be used to implement CNN processor chip or help generate FPGA-based NN accelerators. In general, DeepBurning supports a large family of NN models including CNNs, RNNs to ANNs, and greatly simplifies the design flow of NN accelerators for the machine learning or AI application developers. The generated learning accelerators evaluated with our FPGA board or chip-scale simulation exhibit great power efficiency compared to state-of-the-art manually optimized solutions.
Design Flow of Chip Generator with DeepBurning:
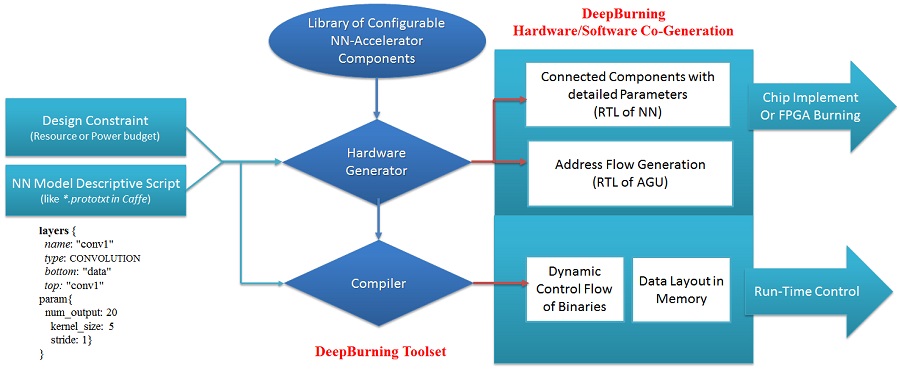
[PDF]
Taming the diversity of Convolutional Neural Network topology
An adaptive data folding and parallelization scheme for deep learning accelerators
Deep convolutional neural networks (CNN) have demonstrated excellent performance in machine vision and recognition area, and sparked a hot trend of research and study on both deep learning algorithms and hardware. Especially, various hardware accelerators have been proposed to support deep CNN based applications, which are known to be both compute-and-memory intensive. Although the most advanced CNN accelerators can deliver high computational throughput, the performance is highly unstable. Once changed to accommodate a new network with different parameters like layers and kernel size, the fixed hardware structure, may no longer well match the data flows. Consequently, the accelerator will fail to deliver high performance due to the underutilization of either logic resource or memory bandwidth. To overcome this problem, we proposed a general deep CNN parallelization scheme based on deep learning accelerators, which offers multiple types of data-level parallelism: inter-kernel, intra-kernel and hybrid. Our design can adaptively switch among the three types of parallelism and the corresponding data tiling schemes to dynamically match different networks or even different layers of a single network. No matter how we change the hardware configurations or network types, the proposed network mapping strategy ensures the optimal performance and energy efficiency. The evaluation shows that, for some layers of the well=known large scale CNNs, it is possible to achieve a speedup of 4.0x- 8.3x over previous state-of-the-art NN accelerator. For the whole phase of network forward-propagation, our design achieves 28.04% PE energy saving, 90.3% on-chip memory energy saving over the prior solutions on average.
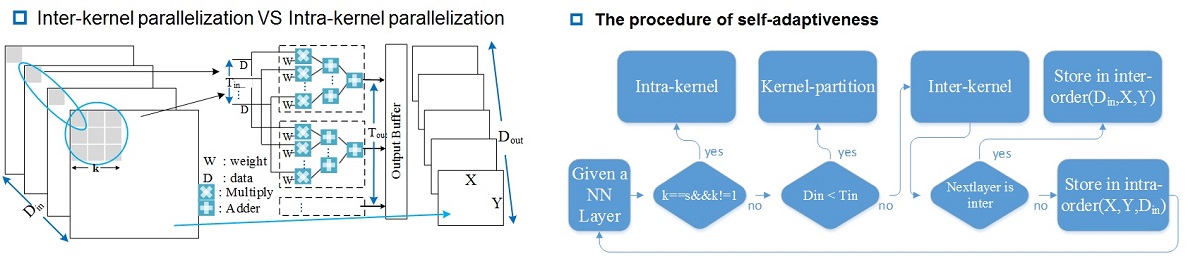
[DAC16][PDF]
Scaling down the machine learning architecture for lightweight devices demanding mobile or always-on intellegence
Deep convolutional neural networks (CNN) are making substantial progress in computer vision, image processing, speech recognition and other Recognition, Mining and Synthesis (RMS) applications. The advent of deep learning architecture is expected to enable machine intelligence in lightweight gadgets such as mobile phones, robotics, micro unmanned vehicles or even IoT devices. Thus, instead of scaling up or out the machine learning architecture as in datacenter, scaling down the machine learning solutions through hardware and software customization is also a interesting research direction, which hopefully gives affordable intellegence to edge devices.
Towards energy-efficient and reliable on-chip memory subsystem for multi-core processors
From data movement perspective, the on-chip memory subsystem of a multi-core processor typically includes both cache and the interconnects between cache banks and cores. Keeping cache and interconnects work reliably in unstable nanometer process and near-threshold voltage supply is critical to the performance and power scalability of memory sub-system as Moore’s Law comes to an end.
- On-chip Interconnects: [TVLSI2015] [ASPDAC2015]
- Cache: [TVLSI2015] [TVLSI2016] [ISCAS2012]
Power and Performance Optimization for DRAM main memory Funded By NSFC
Dynamic Random Access Memory (DRAM) is still the mainstream memory system solution, but has to be re-architected to satisfy the exasperated requirement of recent technology and application trend. As the processors and applications scale, there is a continuous growth of demand for higher DRAM capacity and bandwidth. However, the bandwidth and storage density scaling is greatly constrained by multiple factors such as bus-based communication interface, refresh overhead and failure rate.
- DRAM-to-Processor Interface: [DATE2010] [JCST2014]
- DRAM Refresh: [DAC2015] [ICCAD2014] [ATS2015]
Active NVM: Combating Memory Wall through Near-Memory Computing
The resurrection of Processing-In-Memory is poised to change the landscape of current architecture innovation. Merging computation and storage into the memory system offers a way to detour Memory wall rather than hit it. Instead of pursuing general-purpose computing directly in main memory, we believe it is reasonable to embrace domain-specific acceleration by matching the hardware characteristic of memory device with the behavior of emerging applications such as big data, deep learning and In-Memory Computing (Spark). Fortunately, 3D integration and emerging memory devices, e.g. NVM, are gradually making it happen.
- [DAC2015] [TVLSI2016]
Approximate Accelerator Design based on Neuromorphic Computing Funded By NSFC and SKL
- [DATE2014] [ISCAS2014]
Memory Hierarchy Design with Non-Volatile Memory Technology
- [TVLSI2016] [DAC2011]
Energy efficient machine learning and some of the interesting applications
Deep learning are becoming prevalent in the area of computer vision, recognition and even general-purpose computing through function approximation, and are giving birth to a lot of interesting and innovative applications. Now we are seeking inexpensive but efficient architecture solutions to enable machine learning models in embedded and mobile devices, to make machine better understand and interacts with the real analogue world. Here are some of our demos implemented with embedded development boards based on FPGA or commercial mobile SoCs.